嗯,这一篇文章更多是想分享一下我的网页分析方法。玩爬虫也快有一年了,基本代码熟悉之后,我感觉写一个爬虫最有意思的莫过于研究其网页背后的加载过程了,也就是分析过程,对性能没有特殊要求的情况下,编程一般是小事。
以深圳地区的X房网为例吧。XX房网的主页非常简洁,输入相应的地区就可以找到对应的二手房或者一手房。这一篇文章主要就给大家介绍我在做XX房网爬虫的分析过程。
注意:本文采用Chrome作为分析加载工作,如果使用其他浏览器,请参考具体的规则。
首先想到的嗯,你首先要跳出编程,从使用者甚至是产品经理的角度去思考:在浏览这个页面的时候,如何就能看到全市的二手房的情况。通过主页的一个区一个区的输入,搜索,然后将页面的单元下载,嗯这是一个方法。
![]()
欢迎加入我的QQ群`923414804`与我一起学习,群里有我学习过程中整理的大量学习资料。加群即可免费获取
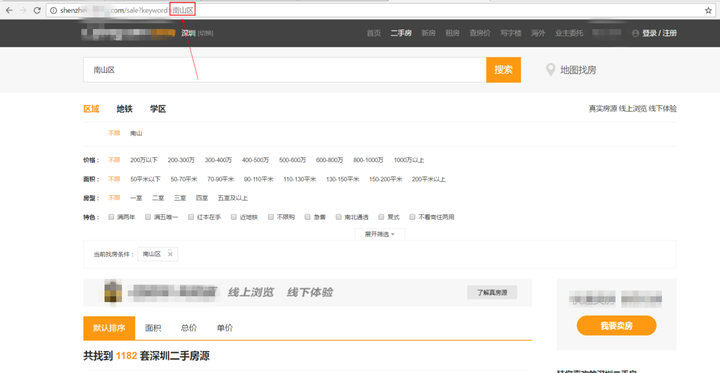
南山区首页的情况
如 上图所示,只要更改keyword后面的参数,就可以获得不同区的二手房数据。编程的时候只需要手动写入一个含有各个区的list,然后通过循环去更改 keyword后面的参数,从而开始一个区域,再爬取其中的链接。这个方法确实是可行的,深圳一共也没有多少个区。这个方法我试过是可行的。
我实际想说的
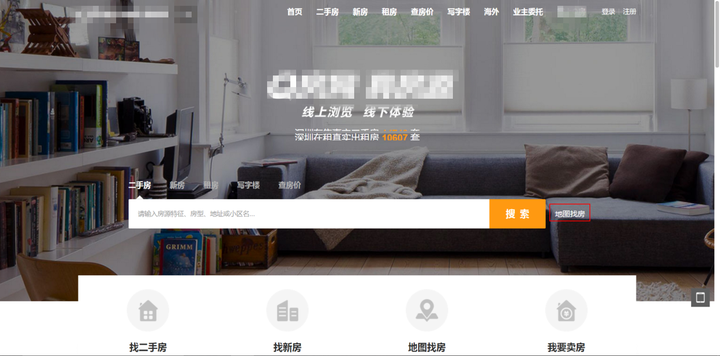
上面的这个方法固然可行,但并不是我想推荐的方法,大家看回首页,搜索栏旁边有一个地图找房。点进去你就能看到深圳全区域的房子,要是能在这里弄个爬虫,不就简单多了。
![]()
地图找房位置
![]()
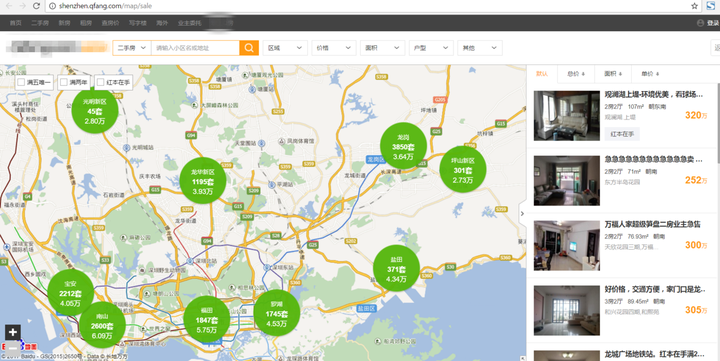
深圳全区域的二手房
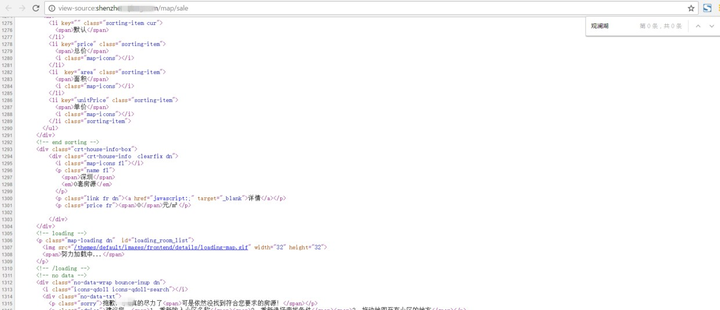
可以看到截图的右侧有所有二手房的链接,我们的任务就是下载右边的所有二手房的数据。首先第一步就先查看页面的源代码(Ctrl+U),可以从右边链表那里 复制一些关键字,在源代码里面找找看,在源代码里面Ctrl+F搜索观澜湖试试,结果是没有,再尝试几个关键词好像都没有,但通过检查元素 (Ctrl+Shift+I),是可以定位到这些关键词的位置。这样可以初步判断右边的链表是通过Js来加载,需要证实。
![]()
关键词观澜湖的在源代码里面的搜索结果
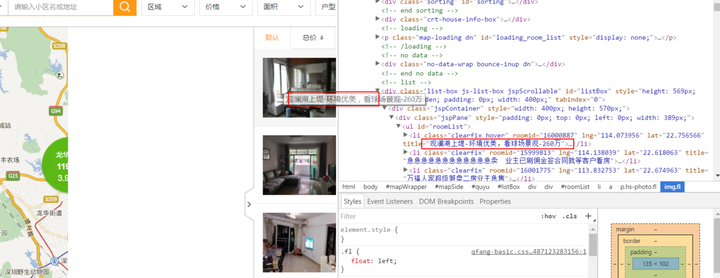
![]()
关键词观澜湖的在页面元素里面的搜索结果
尝试对观澜湖上方的元素在源代码里面定位,例如no-data-wrap bounce-inup dn,就可以在源代码里面找到。仔细对比一下两边的上下文,可以看到在节点下面的内容有非常大的差异。通过这个roomList作为关键词继续查找。
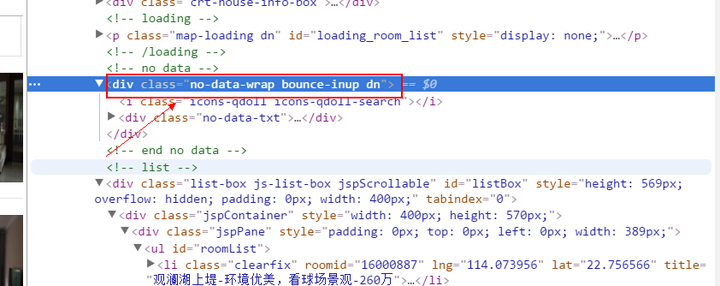
![]()
no-data-wrap bounce-inup dn 在检查元素内的位置
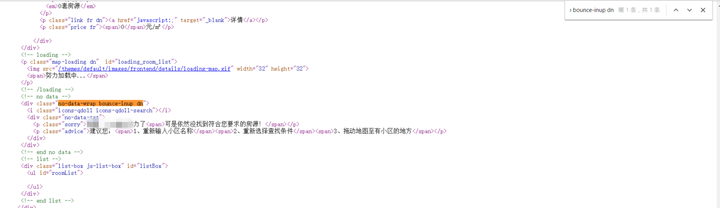
![]()
no-data-wrap bounce-inup dn 在源代码的位置
在检查元素里面可以发现roomList下面的加载的内容就是我们所需要的房屋列表,并且这部分内容再源代码里面没有。而在源代码页通过搜索roomList,却发现出现在script里面,证实roomList里面的内容是通过Js来加载的:
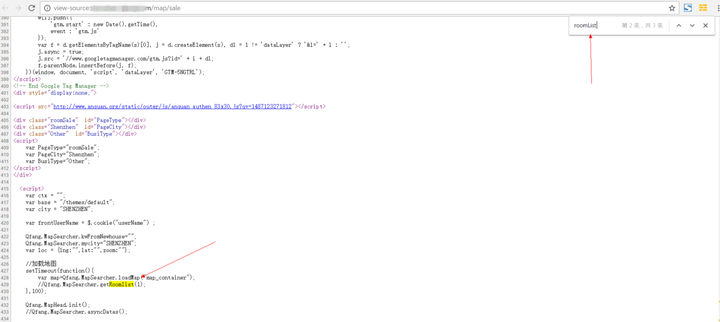
![]()
源代码中roomList出现的位置
下面就变成是找这个roomList了,由于是通过js加载的,打开控制台的network,并重新刷新页面,查看页面里面各个元素的加载过程,在过滤器里面输入roomList,可以找到一条信息:
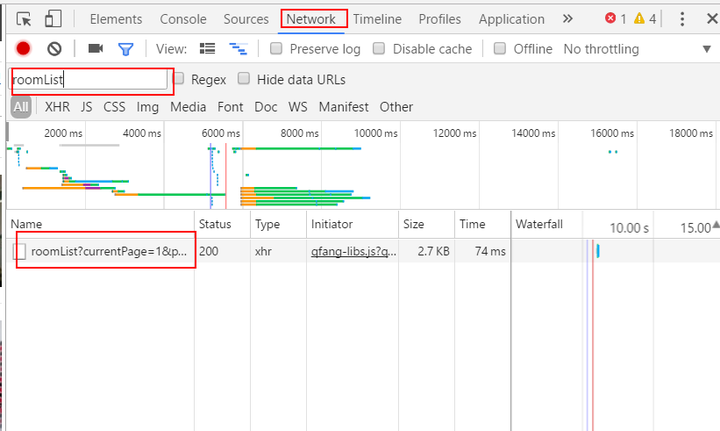
![]()
roomList的搜索结果
点 开看response里面下载的内容,发现那不就是我们要找的东西吗!里面有给出详细的页面数量(roomPageSize),那一个个的八位数字显然就 是每一个房子的id嘛,然后每一页的加载数量是一定的,下面有对应id里面有房子的经纬度、户型、面积以及朝向等等信息(在这里做一个提醒,需要做 heatmap的同学注意了,这里的经纬度用的是百度坐标,如果你后续可视化用的是google地图、高德或者GPS,是需要转换坐标的)。
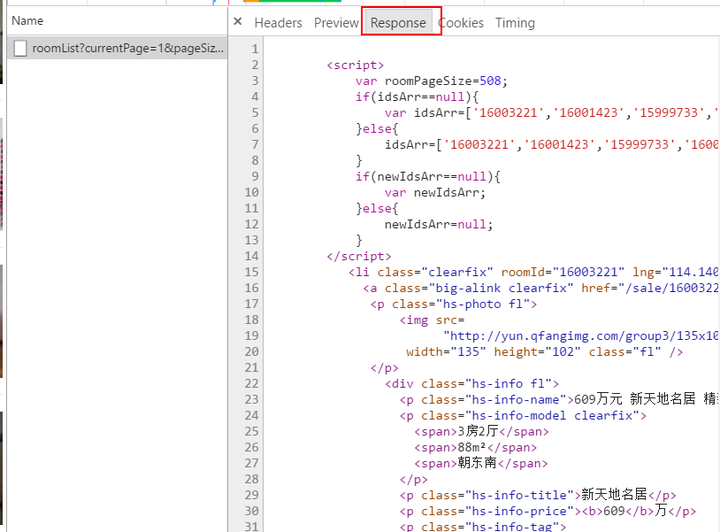
![]()
roomList的内容
找到内容之后,接着就是看他的Headers,看看是如何加载的。
-
-
Request Url表明其访问的链接,Request Method表明他的请求方法是Post;
-
Request的头定义(Headers)里面包括Host、Origin、Referer、User-Agent等;
-
请 求的参数(parameters)里面有三个参数,这三个参数是直接放映在其Url链接上面,里面包括当前页的页码(currentPage)、页面大小 (pageSize)以及s(这个s一开始也不同清楚是什么,但是发现每一次请求都有变化,后面才知道这个是时间戳,表示1970纪元后经过的浮点秒 数);
-
此外Post函数还可以发送数据到服务器做请求,这里所发送的数据包括始末经纬度、gardenId(这个到后期发现是对应的小区编号)和zoom(代表地图上面放大以及缩小的倍数,数字越大,放大倍数越高)
-
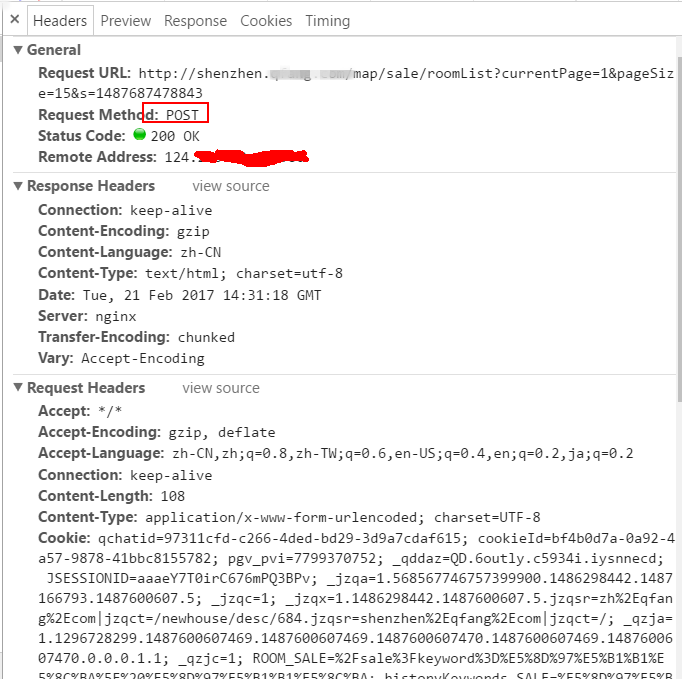
![]()
Header第一页
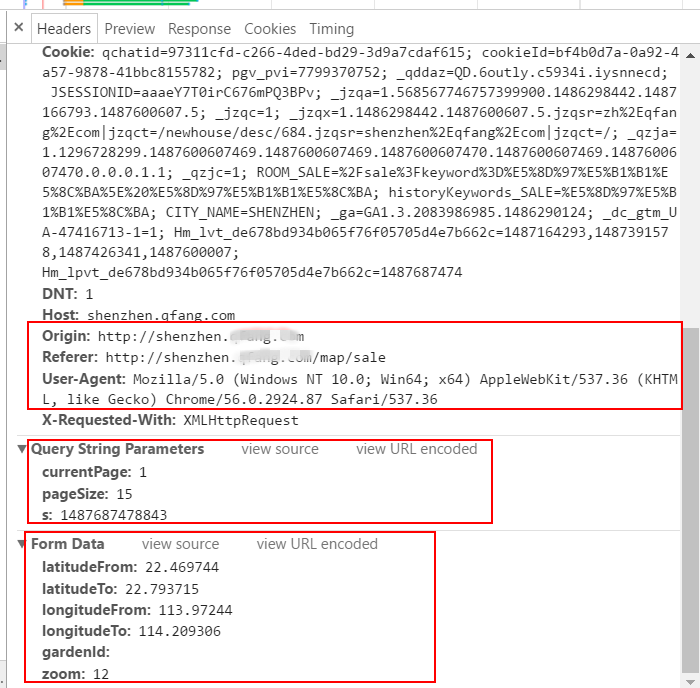
![]()
Herader第二页
基本扒到这里,对整个页面就比较清晰了,也知道我们的爬虫要怎么去写了。
开始写代码了逻辑整理出来后,整个代码就写的非常轻松了。首先通过post方式访问,通过正则表达式提取Reponse里面的roomPageSize,或者最大页数。然后对每一页的内容进行爬取,并将信息输出。
第一部分,加载库,需要用到requests, bs4, re, time(time是用来生成时间戳):
from bs4 import BeautifulSoupimport requests, re, time
第 二部分,通过设定合理的post数据以及headers,通过post下载数据。其中payload里面包括地图所展示的经纬度信息(这个信息怎么获得, 在X房网页面上通过鼠标拖拉,找到合适的位置之后,到控制台Header内查看此时的经纬度就好了),headers则包含了访问的基本信息(加上有一定 的反爬作用):
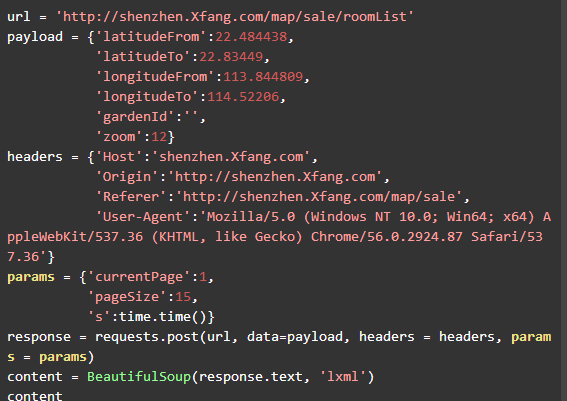
![]()
页面下载后,对于第一次下载首先需要用正则表达式获得最大页面数,我们真正需要的内容结合Beautiful的get和find以及re来抓取就可以了:
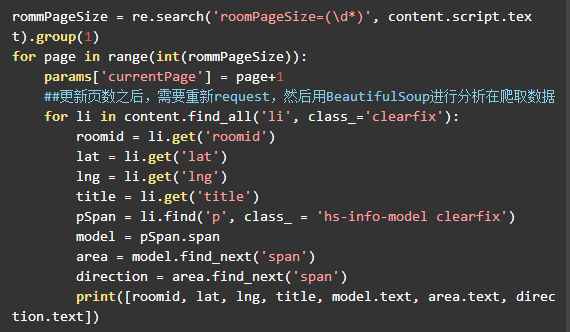
![]()
给一个在控制台里面输出的效果:

![]()